Visual Transfer for Reinforcement Learning via Wasserstein Domain Confusion
by Josh Roy and George Konidaris at AAAI 2021. Full Paper
Motivation
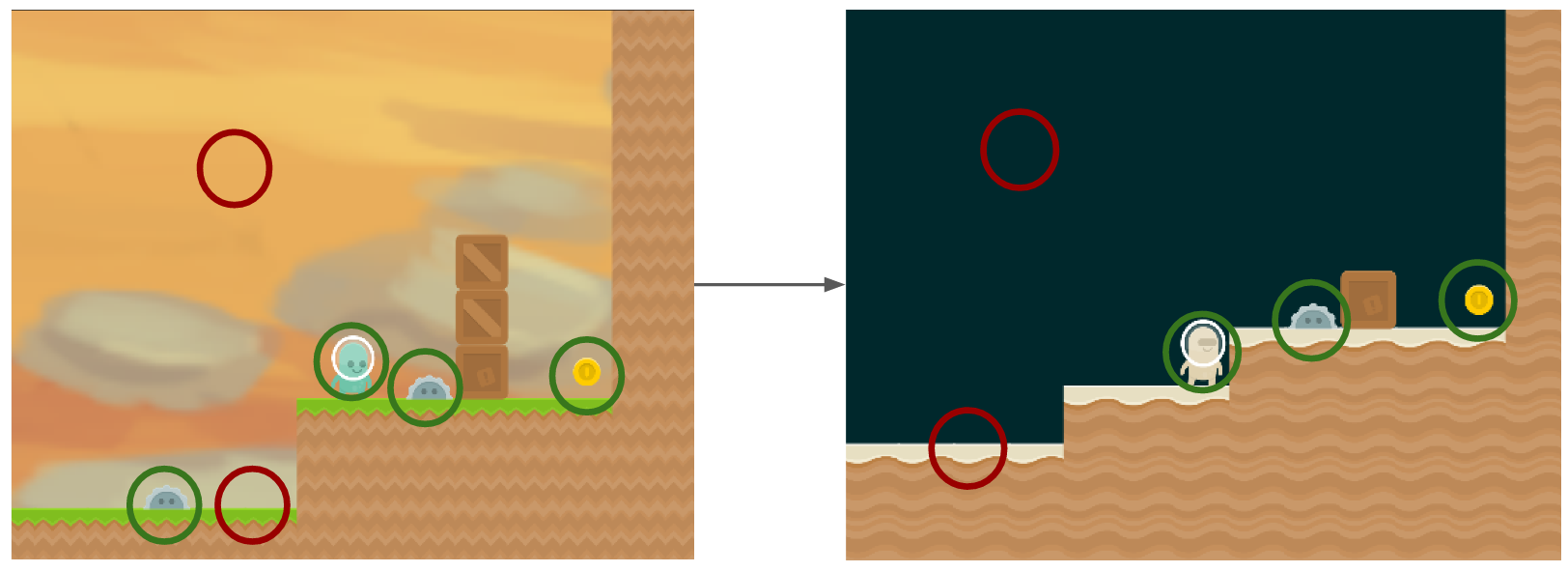
State-of-the-art model-free deep Reinforcement Learning (RL) algorithms frequently overfit to their task, learning “shortcuts” like spurious visual features and memorized action-sequences that enable high training performance but result in low test performance. We decompose the problem and focus on visual transfer between families of related tasks. We present Wasserstein Adversarial Proximal Policy Optimization (WAPPO) that can transfer across different visual variation, such as coinrun pictured below.
Block MDPs
We define visual transfer between a family of related Block Markov Decision Processes (MDPs) \(M \in \mathcal{M}\). These are a subset of Partially Observable MDPs and are defined by an (unobserved) state space \(S\), an observation space \(\mathcal{X}\), an action space \(A\), a transition function \(p(s' \| s, a) \forall s, s' \in S, a \in A\), reward function \(R(s, a) \forall s \in S, a \in A\), and an observation (emission) function \(q(x \| s) \forall x \in X, s \in S\). It assumes that each observation \(x\) maps uniquely to its generating state \(s\). The family \(\mathcal{M}\) is generated by varying \(q\).
Main Contributions
We focus on transfer between a source MDP \(M_s\) and target MDP \(M_t\), assuming the ability to train in \(M_s\) but only a fixed buffer of observations from \(M_t\). When given an observation, our deep RL agent uses an internal representation to decide which action to take. By making this representation invariant to its generating domain, we achieve high transfer performance. Rather than assuming a correspondence between observations from \(M_s, M_t\), we use the Wasserstein-1 distance to align representation distributions, forcing the deep RL agent to learn domain-invariant representations and enabling transfer. For more details, please see the full paper.
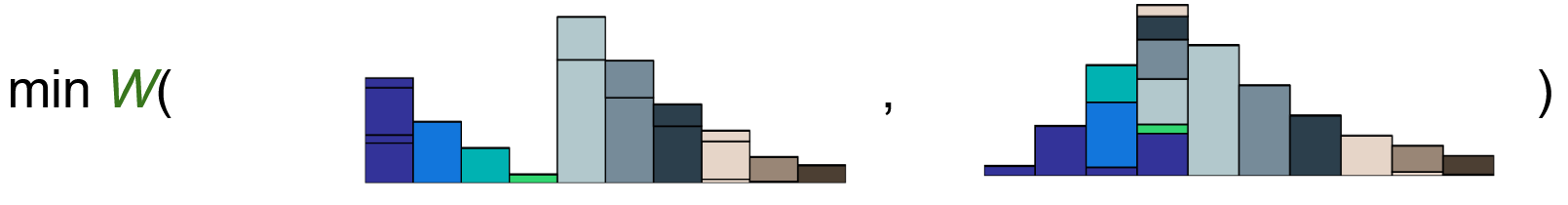
Experimental Results
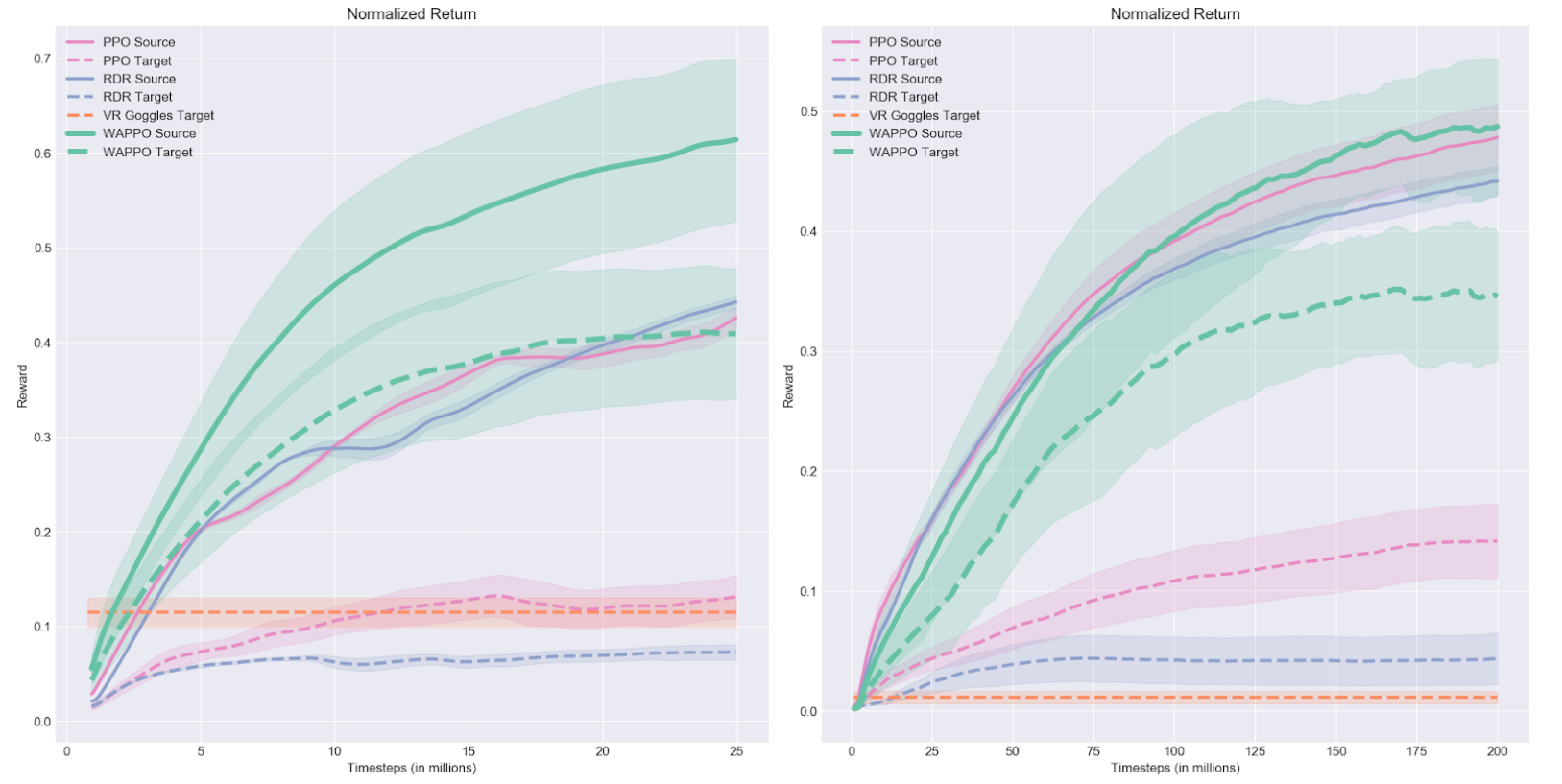
We evaluate on a visual cartpole task as well as both the easy (left) and hard (right) variants of all 16 OpenAI Procgen tasks. Our results are summarized in the graphs below and listed in full detail in our paper.
Takeaways
We have a few interesting takeaways and directions for future research. We empirically demonstrate that distributional alignment of internal representations can boost transfer in Block MDPs. We are further interested to extend these results both to generalization (zero-shot transfer) settings and outside of Block MDPs. Furthermore, we demonstrate that it is not necesary to have direct correspondance between observations in the source and target domain. We are interested (post-covid) in testing these results in transfer between simulation and reality (sim2real) for RL agents deployed on physical robots.